
-
ABOUT ME
-
Hello, I am Akhilesh Kumar
Data Scientist
Self-motivated and hardworking fresher seeking for an opportunity to work in a challenging environment to prove my skills and utilize my knowledge & intelligence in the growth of the organization. I continuously strive to add more firepower in my armory, which drove me to pursue M.tech in Artificial Intelligence at Hyderabad Central University. With scikit-learn as my front-line weapon and Git as main defense, my arsenal flourishes with python and deep learning Keras as support staff.
-
HACKATHONS
-

Titanic: Machine Learning from Disaster
Binary Classification Problem
Learn More
who survived or did not survive the Titanic disaster, can our model determine based on a given test dataset not containing the survival information
Ongoing Project
Participated single
Default Prediction
Binary Classification Problem
Learn More
Data: 18K rows log files (25 features)
Got 82% Accuracy
Participated individually
Stock Prediction
Business case-study
Secured Rank 2nd in terms of accuracy
Participated in team of 5 members
Design Room
Ut condimentum eros bibendum metus lacinia, ac condimentum justo faucibus. Nam nec dui convallis, sodales sapien in, gravida justo. Pellentesque pulvinar massa a nisl iaculis, quis iaculis elit tincidunt.
Learn More
Design Kitchen
Ut condimentum eros bibendum metus lacinia, ac condimentum justo faucibus. Nam nec dui convallis, sodales sapien in, gravida justo. Pellentesque pulvinar massa a nisl iaculis, quis iaculis elit tincidunt.
Learn More
Arsitecture
Ut condimentum eros bibendum metus lacinia, ac condimentum justo faucibus. Nam nec dui convallis, sodales sapien in, gravida justo. Pellentesque pulvinar massa a nisl iaculis, quis iaculis elit tincidunt.
Learn More -
Projects
-

Description:In the field of sentiment analysis for different text genres, relatively less emphasis has been placed on extraction of opinions from scientific literature, more specifically, citations. Citation sentiment detection is an attractive task as it can help researchers in identifying shortcomings and detecting problems, determining the quality of a paper. The Major issue in citation sentiment analysis is that real data is highly unbalance means negative citations are very less compare to positive and neutral Objective: Our research aim is generate minor class article citation artificially using adversial Deep learning approach so that artificially generated article citation will look like real one. We will generate minor class article citation to make data set balance. After that we will apply sentimental analysis. Challenges: Building Varient of GAN and training of GAN is main challange because GAN applied successfully for real valued data like images and text is discrete data. So training GAN for text is research challenge. Research Approach: We are currently doing research to build architecture of Generative Adversial Network(GANs) variant: for text.We are trying to find best deep learning feed forward Network model for GAN’s generator and Discriminator part and trying tofind optimizing and training technique. We are trying to use evolutionary computation for multiobjective optimization. Domain and Technique: Sentimental analysis,NLP, Text Mining, Deep Learning Tools: Nltk, Python, Numpy, Pandas, Sckit-learn, Matplotlib, Keras, Tensorflow
-
Personalized Medicine: Redefining Cancer Treatment
June 2018 to Present Independent Project IDRBTDescription:A cancer tumor can have thousands of genetic mutations. But the challenge is distinguishing the mutations that contribute to tumor growth (drivers) from the neutral mutations.Currently this interpretation of genetic mutations is being done manually.

Data:Data taken from kaggle.We have two data files: one contains the information about the genetic mutations and the other contains the clinical evidence (text) that human experts/pathologists use to classify the genetic mutations.There are nine different classes a genetic mutation. ML problem: Classifies genetic variations.Nine different classes to classify so Multi-class classification problem, Text Mining • Predict the probability of each data-point belonging to each of the nine classes. Metric is Log loss.• Perform Exploratory data Analysis, Data Munging, Text prepossessing, Bag-of-Words, Tf-idf, Naive Bayes, Logistic Regression, Hyperparameter Tuning.
-
Polish companies bankruptcy Prediction
June 2018 to Present Side Mini Project IDRBTDescription:The dataset is about bankruptcy prediction of Polish companies.We have to predict the bankruptcy based on given independent features.

Data:Data taken from kaggle.We have two data files: one contains the information about the genetic mutations and the other contains the clinical evidence (text) that human experts/pathologists use to classify the genetic mutations.There are nine different classes a genetic mutation. Data: Multivariate real valued data set containing 64 columns and 10503 rows obtained from UCI ML repository. ML Problem:Binary Classification problem, We have to predict the bankruptcy by analyzing independent features. • Data Cleaning, prepossessing, Data Imputation,Dimension Reduction using RBM, Feature selection, Visualization,ML Models:Logistic Regression, SVM, Random Forest
-
Predict Quora Question Pairs Having the same Intent using NLP
Dec 2017 to Feb 2018 Side Mini Project UOHDescription:The goal of this project is to predict which of the provided pairs of questions contain two questions with the same meaning.We have to Identify which questions asked on Quora are duplicates of questions that have already been asked.
ML Problem:Text Classification Task. We have to predict about duplicate of the question pair Data: Text data havng question pairss and their ids.Data obtained Kaggle. ML Problem:Binary Classification problem, We have to predict the bankruptcy by analyzing independent features. • Applied Exploratory Data analysis, Feature Extraction, Text Prepossessing, Advance feature Extraction(NLP and Fuzzy Features), Data Visualization T-SNE, TF-IDF weighted word2vec featurization, ML Model: Logistic Regression, Linear SVM, XGBoost
-
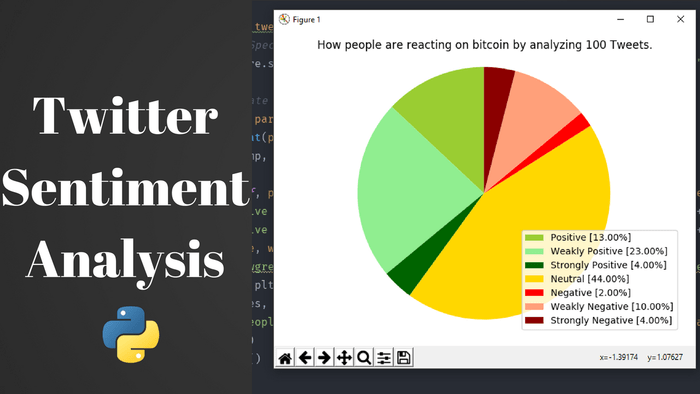
Twitter Sentiment Analysis
10 jan 2018 to 30 march Guided By- Asst. Prof. M. NagamaniThis is my Software engineering lab project in which I implemented sentimental analysis of twitter data. We used lots of natural language processing concept.We trained the bayesian classifier and other classifiers and got the good accuracy. Data set has 1.6 million tweets and got the accuracy of 72%.
-
Recommender System On E-commerce site
10 Dec 2015 to 30 march Guided By- Asst. Prof. V. DamodarnThis is my B.tech Final Year project.This is Big Data analytics project. I have built one site like fli[kart in which anyone can purchase anything. so data is genrated mannualy.We have used the hadoop framework for this. We have used the concept called collaborative filtering .

-
Credit Card Default Prediction
Aug. 2017- Oct. 2017 Guided By-Prof. V.Ravi IDRBTDescription:Taiwan over-issued cash and credit cards,irrespective of their repayment ability, overused credit card for consumption and accumulated heavy credit and cash card debts. The crisis caused to default payment.It become challenge to detect Default payment. Data:Multivariate Default credit card structured data set having 30000 instance and 24 Number of Attributes obtained from UCI ML library.ML Problem:Binary Classification Used the Exploratory data analysis, dimension reduction and feature selection techniques , SVM, KNN, Random forest,Logistic Regression, Ensemble methods
-
SKILLS
-
Programming
-
Frameworks
-
Data Science Techniques
-
CONTACT